
| « earlier | later » |
A reminder that Warsaw Pinboardites are invited to meet me today at 4 PM at the Amatorska café on Nowy Świat 21. Previous announcement here.
—maciej on February 09, 2013
'm organizing a meetup Saturday, January 26 for Pinboard users in Paris. Send me email if you'd like to attend.
—maciej on January 25, 2013
Pinboard Co-Prosperity Winners
Today I am delighted to announce the six projects I have selected for the inaugural round of the Pinboard Co-Prosperity Cloud.
I received 306 applications in total, many of them extremely strong, and narrowing them down to six was not easy. It meant saying no to some very good ideas, and I hope that many people who received a rejection will show me up by creating a successful small business anyway.
The six finalists represent a mix of projects that I think are tractable, useful, clever, and capable of bringing their creators financial independence. They are, in no specific order:
Alex "Skud" Bayley, Australia, Growstuff
Growstuff is a website where food gardeners will be able to track and share their food-growing efforts. A year ago I would have thought Skud's proposal a little idealistic, with its emphasis on process, collaboration, radical openness, and inclusiveness. But my brush with fandom a year ago (when a distributed group of volunteers responded to my call for feature requests by drafting a beautifully organized 50+ page Google doc in about 48 hours) has made a true believer out of me. Moreover, I think food gardening is a natural fit for the kind of community-first approach Skud wants to pursue. I jumped at the chance to pick a project coming out of this friendly, highly collaborative world, and I can't wait to see what it grows into.
Luiz Irber and Guilherme Castelao, Brazil. Low-bandwidth weather forecasts for sailors
If you've ever had to deal with marine weather forecasts, you will immediately see the appeal of this idea. Marine forecasts are poorly organized, often presented in graphical form only, and hard to get where you need them most (on the boat itself, where Internet access costs a fortune). Guilherme and Luiz want to package publicly-available data on currents, wind, and weather into a succinct forecast that sailors can have sent to them by email.
Right now, customized forecasts for boaters exist only at the luxury end of the spectrum, for people who can afford to go out on the water encrusted with expensive electronics. I particularly like that Luiz is a computer engineer in earth sciences, and Guilherme has a PhD in oceanography and is an avid sailor. These guys clearly know what they're up to, and their only remaining barrier to success has been a lack of $37.
Nik White, United States, Simple Cyber Security
Nik is a security guy who wants to offer pre-hardened machine images for cloud services like EC2, Rackspace and VMware. This is such an obviously useful idea that I can't believe it has not been done yet. Like in many areas of computer security, there is no middle ground right now between 'do it yourself for free' and 'pay tens of thousands of dollars to hire an expert'. Securing your own system is time-consuming and very easy to get wrong, and for some projects, you need to meet specific standards. Having canned, hardened AMIs from a trustworthy source fills this gap in the market, allows Nik to partially automate his expertise, and guarantees him a flow of consulting work as an adjunct to his main idea.
Lucas Howell, United States, Board game project
Lucas wants to build a site for fellow board game enthusiasts who want to keep track of their games, remember defeats and triumphs, and compare strategies. Right now this market is dominated by an old and somewhat sprawling site called BoardGameGeek, where the emphasis is more on discovering new games than keeping track of ones you've played in a structured format. BoardGameGeek is also plagued by performance issues and downtime. Lucas thinks there's a good opportunity here for a more focused site, and since these circumstances are almost exactly analogous to the ones that made me create Pinboard as a scrappy alternative to Delicious, I found his pitch persuasive. I also like the fact that Lucas is building something he really wants to use himself.
Bernard Huang, United States. Food By People
The idea behind food by people is a friendly and appealing one: let people sell their home baked goods online. Right now because of antiquated food safety laws this is only legal in 31 states. I believe this is an area that is ripe for regulatory reform, and I'm pleased to support a project that will push at those boundaries. If we can have quasi-legal pot sold online, then the complementary market for baked goods is obviously going to explode. Bernard already has two bakers using the site and making money, always a promising sign. I like the focus of his idea, and I like the idea of not having to pay a fortune to order a box of delicious cookies online.
Indy Griffiths, New Zealand, Parent Interviews
As Indy describes it, his project is "a website where schools sign up, set up an interview evening, and then parents can log in and book their interviews."
It belongs to the group of unglamorous but essential education websites that are currently dominated by crapware. In the US, we have big and awful market leaders like Blackboard.com. In New Zealand, Indy has an established competitor who charges schools a fortune for a terrible user expereince. What particularly impressed me about Indy's idea is that he built a full mockup as part of his scholarship project, and now he's ready to try to make it a viable business. As a recent student, he knows firsthand both what the market needs, and just what makes schools hate the current offering as much as they do. He's clearly thought the idea through and is ready to go forth and sell.
I'll have more to say about each project in a future blog post. Thanks again to everyone who applied, and the many wonderful sponsors who have offered to donate services the winners.
And thanks especially to Jesse Vincent, Diane Person, Ann Hess, Conrad Heiney, Jeff Smith, and Britta Gustafson for helping me with the final selection. Any errors I made are my own, but there would have been more without these nice people.
Congratulations to the winners!
—maciej on January 13, 2013
The Pinboard Co-Prosperity Cloud
For those of you who missed the announcement on Twitter, last week I launched a new startup auto-incubator, the Pinboard Investment Co-Prosperity Cloud. Six selected applicants will receive a tiny amount of funding, along with a generous amount of publicity, to help them launch their sustainable Internet business.
The response so far has been very encouraging. I've received just over 200 submissions, and the overall quality of ideas has been remarkably high. I'm amazed at the response so far, and grateful to everyone who has pitched in with kind words, sponsorship, or taken the time to submit a project.
Applications are open until January 1, and I hope to announce the winners about a week after that.
—maciej on December 26, 2012
I'll be in Japan until January 11. Please email me (maciej@pinboard.in) if you'd be interested in attending a Pinboard meetup in Osaka or in Tokyo. You don't have to speak English! We can just smile and enjoy terrific snacks.
I'll be in Osaka from January 4-8, and in Tokyo from January 8-11. I'm looking forward to meeting, and re-meeting, some of the wonderful Pinboard users here.
—maciej on December 20, 2012
Yesterday, the popular glue website IFTTT removed the ability to perform actions based on Twitter events, due to their reading of recent changes to the Twitter API. A number of Pinboard users have asked me for clarification about what this means for Pinboard, which offers pretty extensive Twitter integration.
Right now, you can connect up to three Twitter accounts to Pinboard, and have the site automatically store your tweets and favorites. Pinboard also lets you export all your archived tweets in JSON format, and makes your tweets searchable. The service is subject to technical restrictions in the Twitter API (which won't return more than the last 3000 or so tweets), but if you set it up early enough, you can maintain an archive going back arbitrarily far.
Recently, Twitter announced a series of new restrictions on how third party services can display tweets to users. Among other things, the display restrictions would make it impossible to continue to make people's tweets searchable, or link them to associated bookmarks in their Pinboard account.
On August 17, I sent an email to Michael Sippey at Twitter, asking him to clarify Twitter's position on archiving:
Hi Michael,
I read your recent blog post with interest, and hope you can clarify the role of personal archives under the new API rules.
For context, Pinboard offers a Twitter archiving service. Users connect their accounts via OAuth and the site downloads and archives their tweets, along with associated bookmarks. These tweets are viewable and searchable on the site, but are only visible to the owner of the account.
Is it Twitter's policy that the tweet display rules be enforced when people are interacting with their own archived Twitter data, in a private client?
I am still waiting for a reply.
My position is straightforward. I believe users have the right to retrieve their own data from any third-party service for the purposes of personal archiving. I believe that they have the right to view and interact with this data without restriction, as long as that view is private to them. For this reason, I don't intend to restrict Pinboard users' ability to manage their archived tweets.
But I also think it's a little early to hoist the black flag. To me, the most plausible theory is that Twitter just didn't think about third-party backup when drafting the new document.
I am optimistic that Twitter will clarify their terms of service with regard to personal backups. In 2012, it remains impossible for a Twitter user to do a full export from their Twitter account. The only way to effectively store and search tweets is through third-party sites.
I don't believe Twitter wants to have the kind of adversarial relationship with their users that a literal reading of their new terms of service would imply, and I look forward to a constructive conversation about it with them.
—maciej on September 28, 2012
I've added tag bundles as an experimental feature. 'Experimental' means I'm going to futz with it without warning, and change the part you like best. Caveat bundlor!
A bundle is a named collection of tags. Say you have a bunch of bookmarks tagged orange, apple, and banana. You can create a bundle called fruit and have it display all bookmarks that have one of those three tags.
Bundles are most useful to people who have highly structured tags, or huge numbers of tags. But they're also handy for creating little thematic collections without having to edit lots of bookmarks at a time.
Here's a screenshot of the bundle editor:
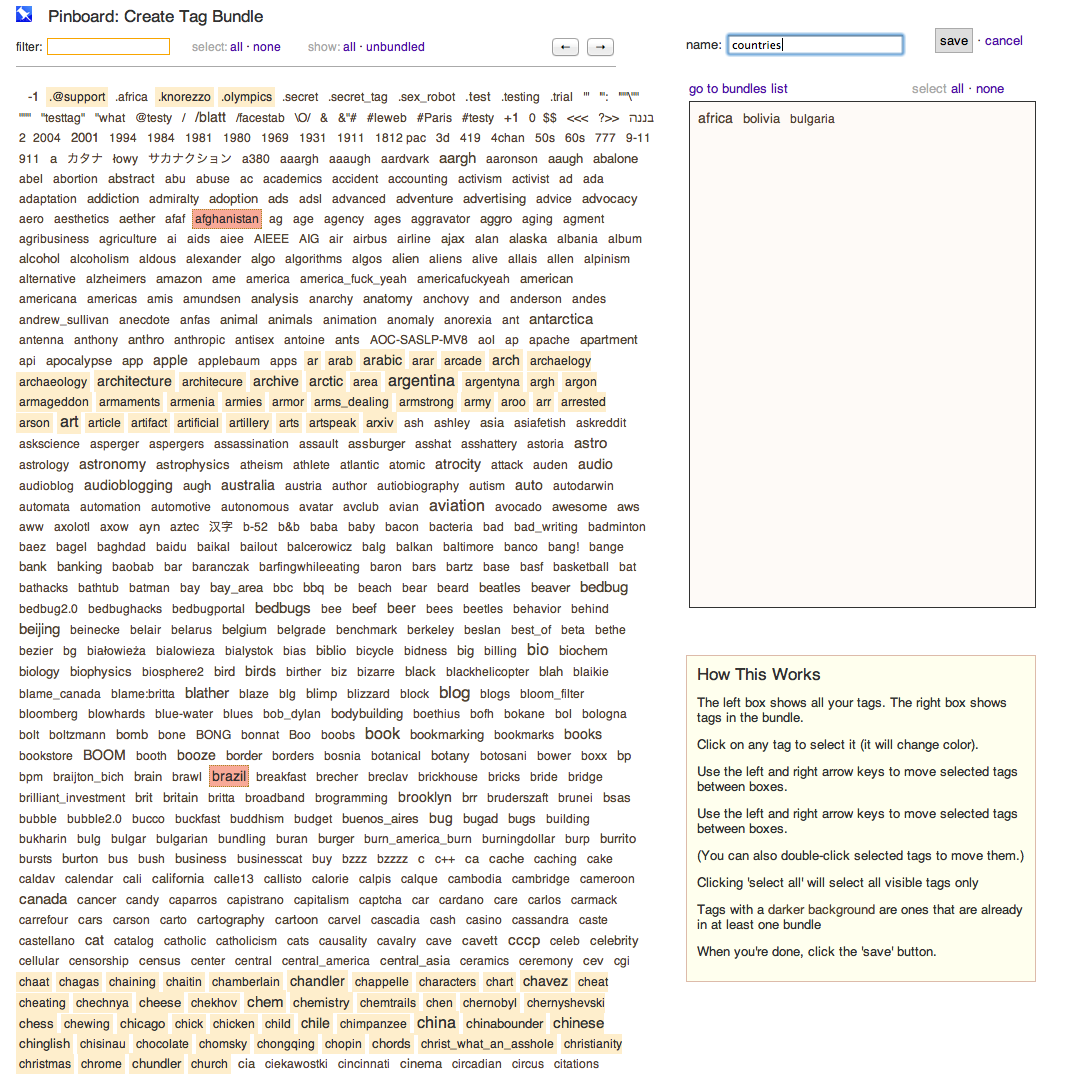
The editor lets you filter tags by prefix, view only unbundled tags, and move tags in and out of a bundle either using the keyboard or by clicking with the mouse. There's no provision right now for seeing or filtering by a list of bundles within the editor, but part of my futzing is coming up with a version of the UI that can do that cleanly.
Here's what your list of bundles will look like in edit mode:

You can order your bundles in arbitrary sequence. You can also make bundles private by prepending a dot to the name, just like private tags.
I'll be adding bundle documentation to the howto page later this weekend. Meanwhile, you can turn on the tag bundles option on your settings page if you are feeling adventurous.
To get started bundling, enable the setting and head back to your user page. You'll see a 'no bundles' link above your tags; click it.
Please send me feedback, either via Twitter or email, and I'll do my best to fold it back in to the feature.
—maciej on August 10, 2012
I first came across the phrase social graph in 2007, in an essay by Brad Fitzpatrick, though I'd be curious to know if it goes back further.
The idea of representing relationships between people as networks is old, but this was the first time I had thought about treating the connections between all living people as one big object that you could manipulate with a computer.
At the time he wrote, Fitzpatrick had two points to make. The first was that it made no sense for every social website to try and recreate the same web of relationships, over and over, by making people send each other follow requests. The second was that this relationship data should not be proprietary, but a common resource that rival services could build on as a foundation.
Fitzpatrick subsequently went to work for Google, and his Utopian vision of open standards and open data became subsumed in a rivalry between Google and Facebook. Both companies now offer their version of a social graph API, and Google (which is trying to catch up) has taken up the banner of open standards and data portability.
This rivalry has brought the phrase 'social graph' into wider use. Last week Forbes even went to the extent of calling the social graph an exploitable resource comparable to crude oil, with riches to those who figure out how to mine it and refine it.
I think this is a fascinating metaphor. If the social graph is crude oil, doesn't that make our friends and colleagues the little animals that get crushed and buried underground?
But right now I would like to take issue with the underlying concept, which I think has two flaws:
I. It's not a graph
The idea of the social graph is that each person is a dot in a kind of grand connect-the-dots game, the various relationships between us forming the lines. Some of these lines may point in one direction (Ted works for Sylvia), while others are reciprocal (Bob is my neighbor). All of them taken together form a mathematical structure called the social graph. Facebook even has a pretty picture!
We nerds love graphs because they are easy to represent in a computer and there is a vast literature on how to do useful things with them. When you ask Google for directions from Detroit to Redwood City, for example, you're interacting with a graph that represents the US road network. The same principle applies any time a site tells you people who bought object X might also be interested in book Y.
In order to model something as a graph, you have to have a clear definition of what its nodes and edges represent. In most social sites, this does not pose a problem. The nodes are users, while edges means something like 'accepted a connection request from', or 'followed', or 'exchanged email with', depending on where you are.
The way you interpret this is another matter - does clicking 'follow' imply you're friends with someone in real life? But at least what the data model represents is unambiguous.
But when you start talking about building a social graph that transcends any specific implementation, you quickly find yourself in the weeds. Is accepting someone's invitation on LinkedIn the same kind of connection as mutually following them on Twitter? Can we define some generic connections like 'fan of' or 'follower' and re-use them for multiple sites? Does it matter that you can see who your followers are on site X but not on site Y?
One way to solve this comparison problem is with standards. Before pooling your data in the social graph, you first map it to a common vocabulary. Google, for example, uses XFN as part of their Social Graph API. This defines a set of about twenty allowed relationships. (Facebook has a much more austere set: close_friends, acquaintances, restricted, and the weaselly user_created).
But these common relationships turn out to be kind of slippery. To use XFN as my example, how do I decide if my cubicle mate is a friend, acquaintance or just a contact? And if I call him my friend, should I interpret that in the northern California sense, or in some kind of universal sense of friendship?

In the old country, for example, we have two kinds of 'friendship' (distinguished by whether you address one another with the informal pronoun) and going from one status to the other is a pretty big deal; you have to drink a toast with your arms all in a pretzel and it's considered a huge faux pas to suggest it before both people feel ready. But at least it's not ambiguous!
And of course sex complicates things even more. Will it get me in hot water to have a crush on someone but have a different person as my muse? Does spouse imply sweetheart, or do I have to explicilty declare that (perhaps on our 20th anniversary)? And should restrainingOrder be an edge or a node in this data model?
There's also the matter of things that XFN doesn't allow you to describe. There's no nemesis or rival, since the standards writers wanted to exclude negativity. The gender-dependent second e on fiancé(e) panicked the spec writers, so they left that relationship out. Neither will they allow you to declare an ex-spouse or an ex-colleague.
And then there's the question of how to describe the more complicated relationships that human beings have. Maybe my friend Bill is a little abrasive if he starts drinking, but wonderful with kids - how do I mark that? Dawn and I go out sometimes to kvetch over coffee, but I can't really tell if she and I would stay friends if we didn't work together. I'd like to be better friends with Pat. Alex is my AA sponsor. Just how many kinds of edges are in this thing?
And speaking of booze, how come there's a field for declaring I'm an alcoholic (opensocial.Enum.Drinker.HEAVILY) but no way to tell people I smoke pot? Why are the only genders male and female? Have the people who designed this protocol really never made the twenty mile drive to San Francisco?
What happens to dead people in the social graph? Facebook keeps profiles around for a while in memoriam, so we probably shouldn't just purge dead contacts from the social graph immediately. But we certainly don't want them haunting us on LinkedIn - maybe there should be a second, Elysian social graph where we can put those nodes to await us?
You can call this nitpicking, but this stuff matters! This is supposed to be a canonical representation of human relationships. But it only takes five minutes of reading the existing standards to see that they're completely inadequate.
Here the Ghost of Abstractions Past materializes in a flurry of angle brackets, and says in a sepulchral whisper:
“How about we let people define arbitrary relationships between nodes…”
(subject,verb,object)
“Maybe even in XML…”
<Person "john"> <likesToShareRecipesWith "susan" /> </Person>
“Of course, we'll need namespaces…”
<ns:Person rdf:about="http://www.example.org/#john"> <ns:likesToShareRecipesWith rdf:resource="http://www.example.org/#susan" /> </ns:Person>
And RDF rises lurching out of the grave to infect the brains of another generation of young developers.
But even if we go ahead and build the Semantic Web, 2004 edition, and populate it with information about all our connections to other people, it still won't be expressive enough.
One big sticking point is privacy. Do I really want to find out that my pastor and I share the same dominatrix? If not, then who is going to be in charge of maintaining all the access control lists for every node and edge so that some information is not shared? You can either have a decentralized, communally owned social graph (like Fitzpatrick envisioned) or good privacy controls, but not the two together.
There's another fundamental problem in that a graph is a static thing, with no concept of time. Real life relationships are a shared history, but in the social graph they're just a single connection. My friend from ten years ago has the same relationship to me as the friend I dined with yesterday. You're left with forcing people (or their software) to maintain lists like 'Recent Contacts' because there is no place in the model to fit this information.
"No problem," says Poindexter. "We'll add a time series of state transitions and exponentially decaying edge weights, model group dynamics as directional flows, and pass a context object in with each query..." and around we go.
This obsession with modeling has led us into a social version of the Uncanny Valley, that weird phenomenon from computer graphics where the more faithfully you try to represent something human, the creepier it becomes. As the model becomes more expressive, we really start to notice the places where it fails.
Personally, I think finding an adequate data model for the totality of interpersonal connections is an AI-hard problem. But even if you disagree, it's clear that a plain old graph is not going to cut it.
II. It's Not Social
The social graph project has roots in something called Friend of a Friend, or FOAF (disclaimer: I worked on a rival project called LOAF, and you may feel free to ascribe everything I say here to purest bitterness).
The idea of FOAF was that everyone would create little XML snippets that represented their interests. For example, if you liked burgers and had a huge crush on your neighbor Matt, you could generate an RDF file that said so and stick it in to your Geocities page.
The problem FOAF ran headlong into was that declaring relationships explicitly is a social act. Documenting my huge crush on Matt in an XML snippet might faithfully reflect the state of the world, but it also broadcasts a strong signal about me to others, and above all to Matt. The essence of a crush is that it's furtive, so by declaring it in this open (but weirdly passive) way I've turned it into something different and now, dammit, I have to go back and edit my FOAF file again.
This is a ridiculous example (though it comes up with strange regularity in the docs), but we run into its milder manifestations all the time. Your best friend from high school surfaces and sends a friend request. Do you just click accept, or do you send a little message? Or do you ignore him because you don't want to deal with the awkward situation? Declaring connections is about as much fun as trying to whittle people from a guest list, with the added stress that social networking is too new for us to have shared social conventions around it.
OkCupid was one of the first social sites to understand that every visible action sent a signal. While other dating sites nagged you to upgrade to an expensive 'Gold' status, which branded you as a foreveralone pariah, OkCupid took pains to make sure people had stuff to do on the site that was unrelated to dating. A popular activity was building and taking personality quizzes. The quiz feature removed some of the stigma from hanging out on the site (I'm just a cool guy having some fun with these quizzes!) while creating a whole new avenue for meeting people.
Social graph proponents seem uninterested in the signaling problem. Leaving aside the technical issues of how to implement it, how does cutting ties actually work socially? Is there any way to be discreet, for example, or have connections naturally degrade over time? In real life, all relationships fade naturally if you don't maintain them, but right now social networks preserve ties in amber until we explicitly break them. Is my sister going to resent me if I finally defriend her annoying husband? Can I unfollow my ex now, or is that going to make her think I'm still hung up on her?
There's no way to take a time-out from our social life and describe it to a computer without social consequences. At the very least, the fact that I have an exquisitely maintained and categorized contact list telegraphs the fact that I'm the kind of schlub who would spend hours gardening a contact list, instead of going out and being an awesome guy. The social graph wants to turn us back into third graders, laboriously spelling out just who is our fifth-best-friend. But there's a reason we stopped doing that kind of thing in third grade!
-:-
You might almost think that the whole scheme had been cooked up by a bunch of hyperintelligent but hopelessly socially naive people, and you would not be wrong. Asking computer nerds to design social software is like hiring a Mormon bartender. Our industry abounds in people for whom social interaction has always been more of a puzzle to be reverse-engineered than a good time to be had, and the result is these vaguely Martian protocols.
But let's say an inspired mathlete proves me wrong. There's a brilliant hack that fixes all the issues I've raised and we go ahead and build the Platonic social graph. What can you actually do with it?
Well, one thing we've seen is that machine-readable lists of friends make it much easier to launch social sites. Letting a thousand startups bloom is one of the big justifications in Fitzpatrick's essay. But is removing this friction a good thing? It is admittedly annoying to have to re-follow people every time you sign up for something, but it also forces the authors to make the site appealing enough to get us over that hurdle. We're already starting to see apps whose first act is to suction down our contact list and spam our various accounts with invites without bothering to woo us at all. I can't imagine having open API access to the social graph is going to improve that.
In other domains, a big graph would be good for recommendations, but friendship is not transitive. There's just no way to tell if you'll get along with someone in my social circle, no matter how many friends we have in common.
But one thing you can do is mine a huge amount of information about my friends and infer things about their interests, income, social status and tastes. And then maybe you can use that information to bring them valuable news and offers, or help them digitally engage with their favorite brands.
Imagine the U.S. Census as conducted by direct marketers - that's the social graph.
Social networks exist to sell you crap. The icky feeling you get when your friend starts to talk to you about Amway, or when you spot someone passing out business cards at a birthday party, is the entire driving force behind a site like Facebook.
Because their collection methods are kind of primitive, these sites have to coax you into doing as much of your social interaction as possible while logged in, so they can see it. It's as if an ad agency built a nationwide chain of pubs and night clubs in the hopes that people would spend all their time there, rigging the place with microphones and cameras to keep abreast of the latest trends (and staffing it, of course, with that Mormon bartender).
We're used to talking about how disturbing this in the context of privacy, but it's worth pointing out how weirdly unsocial it is, too. How are you supposed to feel at home when you know a place is full of one-way mirrors?
We have a name for the kind of person who collects a detailed, permanent dossier on everyone they interact with, with the intent of using it to manipulate others for personal advantage - we call that person a sociopath. And both Google and Facebook have gone deep into stalker territory with their attempts to track our every action. Even if you have faith in their good intentions, you feel misgivings about stepping into the elaborate shrine they've built to document your entire online life.
Open data advocates tell us the answer is to reclaim this obsessive dossier for ourselves, so we can decide where to store it. But this misses the point of how stifling it is to have such a permanent record in the first place. Who does that kind of thing and calls it social?
III What, then, is to be done?
The funny thing is, no one's really hiding the secret of how to make awesome online communities. Give people something cool to do and a way to talk to each other, moderate a little bit, and your job is done. Games like Eve Online or WoW have developed entire economies on top of what's basically a message board. MetaFilter, Reddit, LiveJournal and SA all started with a couple of buttons and a textfield and have produced some fascinating subcultures. And maybe the purest (!) example is 4chan, a Lord of the Flies community that invents all the stuff you end up sharing elsewhere: image macros, copypasta, rage comics, the lolrus. The data model for 4chan is three fields long - image, timestamp, text.
Now tell me one bit of original culture that's ever come out of Facebook.
Right now the social networking sites occupy a similar position to CompuServe, Prodigy, or AOL in the mid 90's. At that time each company was trying to figure out how to become a mass-market gateway to the Internet. Looking back now, their early attempts look ridiculous and doomed to failure, for we have seen the Web, and we have tasted of the blogroll and the lolcat and found that they were good.
But at the time no one knew what it would feel like to have a big global network. We were all waiting for the Information Superhighway to arrive in our TV set, and meanwhile these big sites were trying to design an online experience from the ground up. Thank God we left ourselves the freedom to blunder into the series of fortuitous decisions that gave us the Web.
My hope is that whatever replaces Facebook and Google+ will look equally inevitable, and that our kids will think we were complete rubes for ever having thrown a sheep or clicked a +1 button. It's just a matter of waiting things out, and leaving ourselves enough freedom to find some interesting, organic, and human ways to bring our social lives online.
—maciej on November 08, 2011
I've added the ability to create a public profile on the site. This lets you specify your contact info on various other websites and provide a little information about yourself. You can choose to have your profile visible just to Pinboard users or to the entire Internet.
Here's what mine looks like:
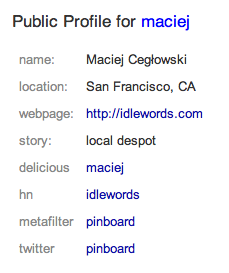
The purpose of these profiles is to let people find one another on the site and build (or re-build) their networks. Naturally, like all social features on Pinboard, this one is strictly opt-in. If you'd like to create your own profile, go to settings -> privacy and click the friendly checkbox. You'll see a new 'profile' tab appear in your navigation bar.
And if you're curious, you can find a full list of users with profiles on the pinboard.in/directory page. I've been getting a big kick out of the variety of people and responses showing up there.
—maciej on November 03, 2011
Show URLs and Alphabetized Tags
I added two new bookmark display options this weekend:
Show URLs will display the full URL of every bookmark underneath the title.
Alphabetize Tags will always display your bookmark tags in that order, rather than the order they were entered.
To make things a little cleaner, I've broken these and related options out into a 'Bookmark Display' subsection on the settings page.
—maciej on October 31, 2011
| « earlier | later » |
Pinboard is a bookmarking site and personal archive with an emphasis on speed over socializing.
This is the Pinboard developer blog, where I announce features and share news.
How To Reach Help
Send bug reports to bugs@pinboard.in
Talk to me on Twitter
Post to the discussion group at pinboard-dev
Or find me on IRC: #pinboard at freenode.net