
| « earlier | later » |
This week Pinboard was profiled on Time.com, in an article about foreveralone entrepreneurs, along with more glamorous fellow-traveler, Instapaper. I really like the stock photo of ferocious productivity at the top of the article. You must picture me off frame to the right, squinting and rubbing my temples. (You know it's a stock photo when the laptop's not a Mac).
The article doesn't say much I haven't already written about here, except for some details about total revenue. You guys have given me a Google salary this year and I am extremely grateful for that!
—maciej on October 27, 2011
Spikes, Logs and the POWER CLAW
Before launching Pinboard I created the usual ritual series of spreadsheets to try to anticipate traffic, data storage requirements, and revenue given a variety of scenarios. And like everybody else I have found these spreadsheets to bear little relationship to reality.
The problem with trying to model this stuff is that we find ourselves in a domain where a small number of rare events can completely dominate the data. Here's an all-time graph of new Pinboard users per day, for example:
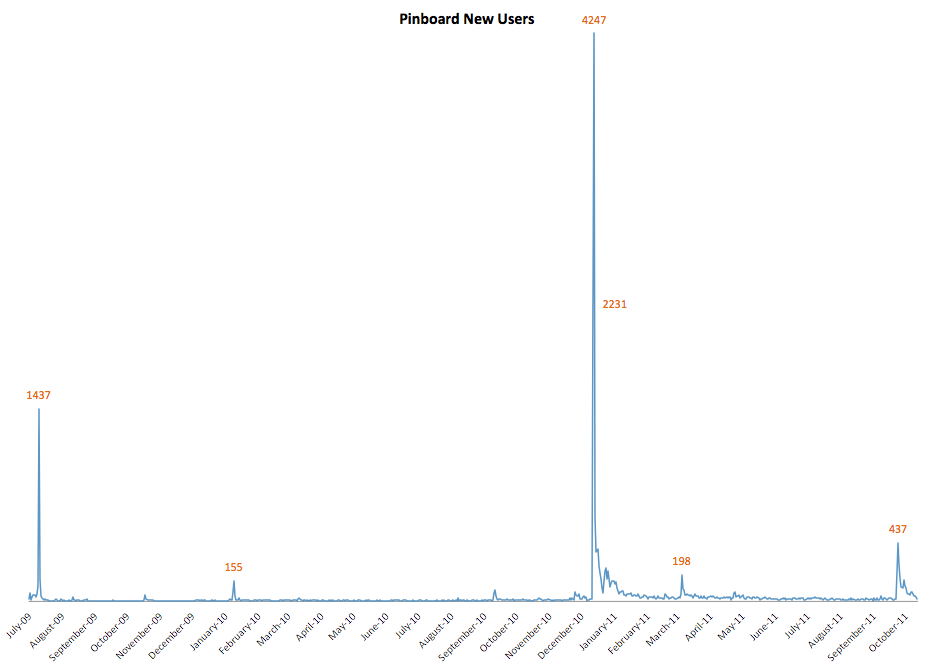
This chart shows user signups over time, but you'd see the same graph for every metric of interest - traffic, Twitter mentions, cups of coffee consumed by the developer. Just seven days account for half of all Pinboard revenue.
The mechanics of this are fmailiar. Someone writes an article about you, or you're featured on a Top 10 list, or a meteor hits your competitor and very briefly the full attention of bored people on the Internet is yours.
Somewhat counterintuitively, while the timing and size of the events is unpredictable, the overall pattern is regular. Here's what the same graph looks like if you rank all the days by number of new users and plot them on a log-log scale:
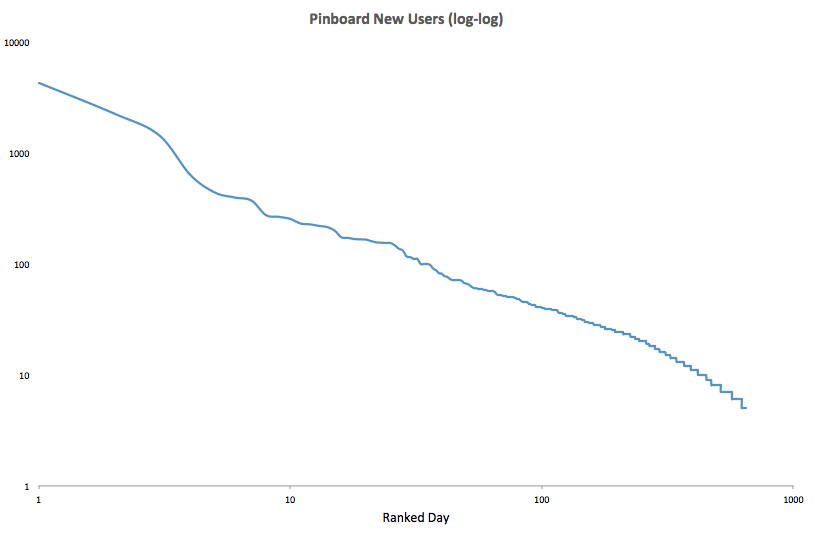
This kind of plot is the hallmark of the POWER CLAW. If your stats look like this, you can know with some confidence that your day-to-day experience will not prepare you for a few extraordinary days that will matter most for your project.
You can also expect to spend most of your time grinding away, waiting for those extraordinary days to arrive. Rare events are rare - it says so right there in the name!
Of course, many other people have noticed this phenomenon, and there's a terrific book
devoted entirely to it. But there's something about human psychology that makes it very hard to internalize the idea. I'm still making the damned spreadsheets.
If you run a web thing, please consider sharing your own log-log plot with the world, obfuscating whatever you need to to feel comfortable. I'm very curious about how many young sites see a similar traffic pattern, and whether it diminishes as you grow.
---
* Back around 2003 the blog world became fascinated with power laws and exponential distributions due to a Clay Shirky essay. POWER CLAW has been my mental shorthand for this kind of beard-stroking ever since.
—maciej on October 16, 2011
I've had a couple of emails and tweets asking somewhat cautiously why the popular page has filled with slash fiction. That's because the fans are coming!
I learned a lot about fandom couple of years ago in conversations with my friend Britta, who was working at the time as community manager for Delicious. She taught me that fans were among the heaviest users of the bookmarking site, and had constructed an edifice of incredibly elaborate tagging conventions, plugins, and scripts to organize their output along a bewildering number of dimensions. If you wanted to read a 3000 word fic where Picard forces Gandalf into sexual bondage, and it seems unconsensual but secretly both want it, and it's R-explicit but not NC-17 explicit, all you had to do was search along the appropriate combination of tags (and if you couldn't find it, someone would probably write it for you). By 2008 a whole suite of theoretical ideas about folksonomy, crowdsourcing, faceted infomation retrieval, collaborative editing and emergent ontology had been implemented by a bunch of friendly people so that they could read about Kirk drilling Spock.
Fan culture is extremely collaborative, and its participants had rapidly taught one another how best to combine LiveJournal, Delicious and other sites into an network for sharing and discovery that, due to the social stigma of the hobby, remained under the radar even though it would have meant instant success for any entrepreneur sincerely willing to work with them. Fans shared their setups and workflows with each other in much the way that startup subculture obsesses over tool chains and "stacks". The whole thing reminds me a lot of what HyperCard was like in the nineties, right before its demise, when a large number of otherwise non-technical users had basically taught themselves to do elaborate programming with the tool, and were doing amazing things with it. Until, of course, Apple pulled the plug.
Avos did a similar thing last week when they relaunched Delicious while breaking every feature that made their core users so devoted to the site (networks, bundles, subscriptions and feeds). They seemed to have no idea who their most active users were, or how strongly those users cared about the product. In my mind this reinforced the idea that they had bought Delicious simply as a convenient installed base of 'like' buttons scattered across the internet, with the intent of building a completely new social site unrelated to saving links.
For any bookmarking site, the fan subculture is valuable because it makes such heavy and creative use of tagging, and because they are great collaborators. I can't think of a better way to stress-test a site then to get people filling it with Inception fanfic. You will get thoughtful, carefully-formatted bug reports; and if you actually fix something someone might knit you a sweater. And please witness the 50 page spec, complete with code samples, table of contents, summary, tutorial, and flawless formatting, the community produced in about two days after I asked them in a single tweet what features they would want to see in Pinboard*. These people do not waste time.
They're also smart enough to realize that in the long run, they need to take control of their own bookmarking in order to avoid these kinds of surprises. One way they've done this is through what Britta calls the "friendliest goddamn open source project ever", an Archive of our Own. But this project is not quite ready to carry the full burden of everyone's bookmarks.
Pinboard is not a social site, and it has always been about archiving, not sharing. I don't intend to make the same mistake Avos did and suddenly try to retool the site for a brand new group while neglecting the quiet link hoarders who form the Pinboard old guard. As a grouchy hermit, I like to think that other grouchy hermits should have a place to store stuff that will never feel like publishing or expose them to unwanted contact with other people.
At the same time, I think the fans are a very nice bunch who have been somewhat hard done by, and that their presence will be a long-term boon to the site. Like bees in a garden, the sudden arrival of a big swarm can be alarming, but all this swarm wants is a place to set up a hive and get to work. And I'll end this metaphor right now before it provokes any pollination slash.
In the long run it's healthier for the site to have a more varied user base, and this is a group of users with a terrific track record of constructive feedback on other sites (notably LiveJournal) and a committment to privacy and non-commercialism that I think a lot of our original users share.
In a word: don't be afraid. Nobody has pivoted, nothing is changing. Just be careful what you click on for a while.
I'll post in a couple of days about what I'm planning to work on this fall, including my response to that epic feature spec. In the meantime I'll be hanging around Twitter and on pinboard-dev, as ever.
* naturally, they also produced this.
—maciej on October 02, 2011
What happened?
Pinboard runs on servers in a Virginia datacenter. On Tuesday the FBI raided the data center and confiscated some computer equipment from our service provider, DigitalOne. This equipment included our main database server. The server was returned about a day later and is back online.
Pinboard was offline for several hours during the raid, and ran with reduced capabilities for about four days after that.
Are my bookmarks safe?
Yes. Our servers are set up so that if one fails or goes offline, the other has a full copy of the data. (For the technically minded, we use a master-master replication setup with writes going to a single master). When the FBI took the main database server away, there was an up-to-date copy available on the backup server. We also continued making daily database backups to Amazon S3 during the outage.
Why did the FBI take a Pinboard server?
I don't know. As best I can tell, the FBI was after someone else whose server was in physical proximity to ours. The kind of computer we lease is a 'blade server', which means there are about a dozen of them arranged in each computer enclosure, like books on a shelf. If the FBI took an entire enclosure (or more), it would explain why so many servers went offline. I also understand it is routine in raids like this to remove as much equipment as necessary to preserve the chain of evidence and prevent suspects from covering their tracks.
It is not possible to tell at this point whether the scope of the raid was excessive. I'm trying to find out the details of what happened and will share whatever I learn.
Does the FBI have my bookmarks?
In order for the FBI to collect this data, they would need a warrant for it. At this point I have no reason to believe our site was included in the warrant. A FOIA request for the warrant has been filed and we should be able to see it within about two weeks.
What was on the confiscated server?
The server had a full copy of our database, the Pinboard source code, and contained archived web pages from about half our archival users.
Is my password safe?
This depends on how much you trust the FBI. Pinboard passwords are stored as salted SHA1 hashes, so you should assume that the FBI could easily crack your password if they wanted to. I'm in the process of moving to a safer form of password encryption (bcrypt) but at the time of the raid the user table still contained both forms of encrypted password.
An instapaper server containing Pinboard passwords was also seized during the raid. Those passwords were (for all practical purposes) stored unencrypted. If you connected your Instapaper and Pinboard accounts at any point you should change your Pinboard password wherever you use it.
Will bookmarks that I added on the backup server stay in my account?
Yes.
Is it still safe to use Pinboard?
It is as safe as it was before the raid. Our top priority is to avoid losing user data. But please, always make backups.
How can I be sure this won't happen again?
I'll be making several changes to how the site is hosted to make sure a data center failure can't affect us this badly again, and I'll post about them here shortly.
How can I get my data off of Pinboard and close my account?
Use the export page to grab your bookmarks, then send me an email.
—maciej on June 25, 2011
Since Pinboard has collected a lot of bookmarks at this point, I thought it would be interesting to actually run the numbers on link rot - the depressing phenomenon in which perfectly healthy URLs stop working just a few years after appearing online.
Link rot in my own bookmarks is what first inspired me to create Pinboard, a personal archive disguised as a social bookmarking site. As I've shilled before, Pinboard is the only website that will store full page content for the kind of champagne-swilling fat cats willing to pay us a $25/year fee.
But while link rot motivated me to build the site, until recently I did not have enough user data to actually quantify the problem. I was particularly curious to see whether link rot would be linear with time, or if links would turn out to have a half-life, like plutonium. Here's what I found:
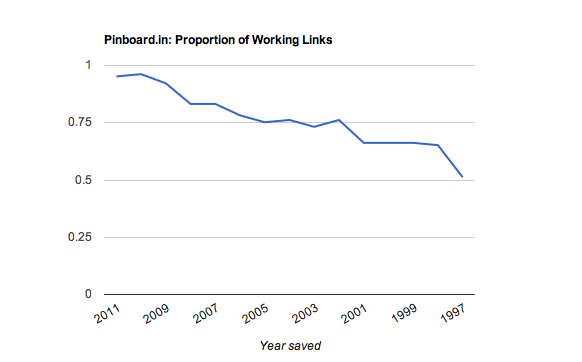
To make the pretty graph, I wrote a script that pretended to be a recent version of Safari (with cookies enabled) and sampled 300 URLs at random for each year between 1997 and 2011. Pinboard has only existed since 2009, but the site preserves the stated bookmark creation date on import, and many of our users have been bookmarking since the days of clay tablets and gopher. I excluded all private bookmarks from the data set.
Along with the pretty graph, I've published the detailed results by year here. Links appear to die at a steady rate (they don't have a half life), and you can expect to lose about a quarter of them every seven years.
Now for some methodological hemming and hawing.Measuring link rot with a computer program is tricky because URLs have a number of different decay products:
- Truly dead links. These give an HTTP error code and are easy to catch.
- Page gone, site lives on. Many sites use a boilerplate 'Not Found' page, that returns a valid (200) HTTP status code. To the naive crawler, this looks like a live link. To catch these dead links, I performed an additional check for the number '404' or the phrase 'not found' (case insensitive) appearing in the page title.
- Redirected for your convenience. Some sites redirect their dead link traffic to a landing page they think will be useful to you or lucrative to them. Newspaper sites seem to be particularly fond of this approach. The only way to check for this is by actually clicking each link.
- Dead domains. When a whole domain dies, it tends to end up as a 'parked domain' page stuffed with ads. This looks superficially like a normal web page and returns a successful (200) status code.
Lacking the time to check links by hand, I was only able to catch dead links in categories 1 and 2.
Another problem with my data sample is that it does not include URLs that people pruned from their bookmarks, either when they imported into Pinboard or later on. So there's some survivor bias here making links look more durable than they are.
Since we don't have more than a few thousand URLs from before 2000, I would put less faith in the numbers for older links. In more recent years I was able to draw from a pool of tens of thousands of URLs, so I have more confidence in those results.
In addition to the pretty graph, I've put up detail pages showing the URL data for each year, as well as a raw dataset of URLs and their associated HTTP codes if you'd like to do your own analysis. Please let me know if you do and I'll link it from this blog
I would also be very interested to see this kind of analysis from other sites that collect user-submitted links, particularly ones that have been around for a while. The Wikipedia page on link rot links to a number of research papers on the topic (download them quick, while they're still accessible!). Unfortunately many of these are marred by either focusing on an overly specific species of link ('scholarly publications' or other .edu crap) or covering a short span of time.
Here are some of my own open questions regarding link rot:
- How many of these dead URLs are findable on archive.org?
- What is the attrition rate for shortened links?
- Is there a simple programmatic way to detect parked domains?
- Given just a URL, can we make any intelligent guesses about its vulnerability to link rot?
Please catch me on email or Twitter if you can shed any light, or if I've made big mistakes in the data analysis.
—maciej on May 26, 2011
A number of people asked about the technical aspects of the great Delicious exodus of 2010, and I've finally had some time to write it up. Note that times on all the graphs are UTC.
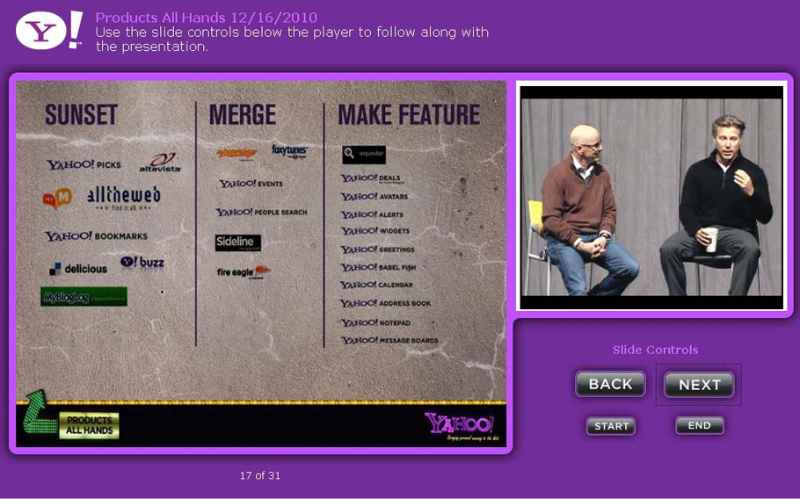
On December 16th Yahoo held an all-hands meeting to rally the troops after a big round of layoffs. Around 11 AM someone at this meeting showed a slide with a couple of Yahoo properties grouped into three categories, one of which was ominously called "sunset". The most prominent logo in the group belonged to Delicious, our main competitor. Milliseconds later, the slide was on the web, and there was an ominous thundering sound as every Delicious user in North America raced for the exit. [*]
{kind=link}
I got the message just as I was starting work for the day. My Twitter client, normally a place where I might see ten or twenty daily mentions of Pinboard, had turned into a nonstop blur of updates. My inbox was making a kind of sustained pealing sound I had never heard before. It was going to be an interesting afternoon.
Before this moment, our relationship to Delicious had been that of a tick to an elephant. We were a niche site and in the course of eighteen months had siphoned off about six thousand users from our massive competitor, a pace I was was very happy with and hoped to sustain through 2011. But now the Senior Vice President for Bad Decisions at Yahoo had decided to give us a little help.
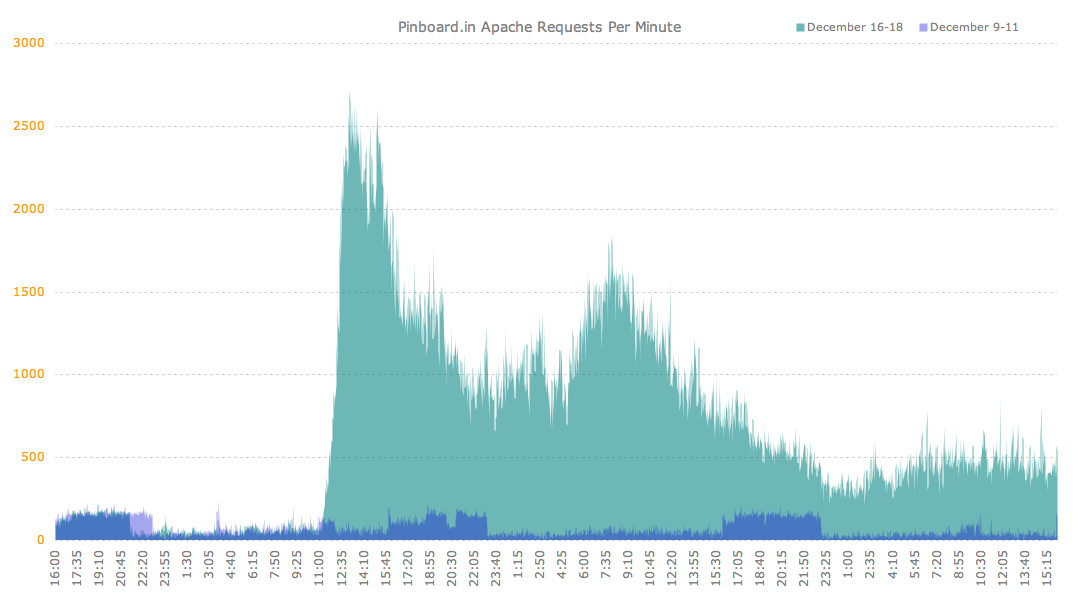
I've previously posted this graph of Pinboard web traffic on the days immediately before and after the Delicious announcement. That small blue bar at bottom shows normal traffic levels from the week before. The two teal mountain peaks correspond to midday traffic on December 16 and 17th.
My immediate response was to try to log into the server and see if there was anything I could to do keep it from falling over. Cegłowski's first law of Internet business teaches: "Never get in the way of people trying to give you money", and the quickest way to violate it would have been to crash at this key moment. To my relief, the server was still reachable and responsive. A glance at apachetop showed that web traffic was approaching 50 hits/second, or about twenty times the usual level.
This is not a lot of traffic in absolute terms, but it's more than a typical website can handle without warning. Sites like Daring Fireball or Slashdot that are notorious for crashing the objects of their attention typically only drive half this level of traffic. I was expecting to have to kill the web server, put up a static homepage, and try to ease the site back online piecemeal. But instead I benefitted from a great piece of luck.
Pinboard shares a web server with the Bedbug Registry, a kind of public forum for people fighting the pests. I started the registry in 2006 (a whole other story) and it existed in quiet obscurity until the summer of 2010, when bedbugs infested some high-profile retail stores in New York City and every media outlet in the country decided to run a bedbug story at the same time.
The Summer of Bug culminated in a September link from the CNN homepage that drove a comparable volume of traffic (about 45 hits/second) and quickly turned the server to molasses. At that point Peter spent a frantic hour reconfiguring Apache and installing pound in order to safely absorb the attention. Neither of us realized we had just stress-tested Pinboard for the demise of Delicious three months later. [**]
Thanks to this, the Pinboard web server ran like a champ throughout the Delicious exodus even as other parts of the service came under heavy strain. We were able to keep our median page display times under a third of a second through the worst of the Yahoo traffic, while a number of other sites (and even the Delicious blog!) went down. This gave us terrific word-of-mouth later.
Of course, had bedbugs been found in the Delicious offices, our server would have been doomed.
Another piece of good luck was that I had overprovisioned Pinboard with hardware, basically due to my great laziness. Here's what our network setup looked like on that fateful day:
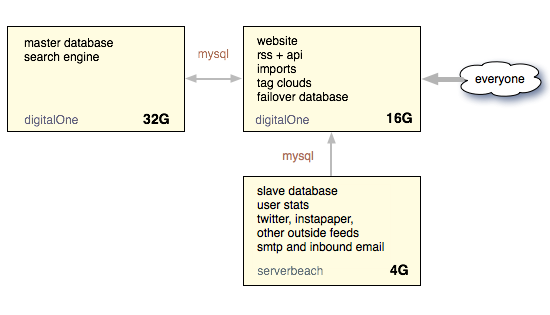
As you can see, we had a big web server connected to an even bigger database server, with a more modest third machine in charge of background tasks.
It has become accepted practice in web app development to design in layers of application caching from the outset. This is especially true in the world of Rails and other frameworks, where there is a tendency to treat one's app like a high-level character in a role-playing game, equipping it with epic gems, sinatras, capistranos, and other mithril armor into a mighty "application stack".
I had just come out of Rails consulting when I started Pinboard and really wanted to avoid this kind of overengineering, capitalizing instead on the fact that it was 2010 and a sufficiently simple website could run ridiculously fast with no caching if you just threw hardware at it. After trying a number of hosting providers I found Digital One, a small Swiss company that rented out HP blade servers with prodigious (at least by web hosting standards) quantities of RAM. This meant that our two thousand active users were completely swallowed up within a vast, cathedral-like database server.
If you offer MySQL this kind of room, your data is just going to climb in there and laugh at you no matter what kind of traffic it gets. Since Pinboard is not much more than a thin wrapper around some carefully tuned database queries, users and visitors could page through bookmarks to their hearts' content without the server even noticing they were there. That was the good news.
The bad news was that it had never occurred to me to test the database under write load.
Now, I can see the beardos out there shaking their heads. But in my defense, heavy write loads seemed like the last thing Pinboard would ever face. It was my experience that people approached an online purchase of six dollars with the same deliberation and thoughtfulness they might bring to bear when buying a new car. Prospective users would hand-wring for weeks on Twitter and send us closely-worded, punctilious lists of questions before creating an account.
The idea that we might someday have to worry about write throughput never occurred to me. If it had, I would have thought it a symptom of nascent megalomania. But now we were seeing this:

There were thousands of new users, and each arrived clutching an export file brimming with precious bookmarks. Within a half hour of the onslaught, I saw that imports were backing up badly, the database was using all available I/O for writes, and the two MySQL slaves were falling steadily behind. Try as I might, I could not get the imports to go through faster. By relational database standards, 80 bookmark writes per second should have been a quiet stroll through a fragrant meadow, but something was clearly badly broken.
To buy a little time, I turned off every non-essential service that wrote anything to the database. That meant no more tag clouds, no bookmark counts, no pulling bookmarks from Instapaper or Twitter, and no popular page. It also meant disabling the search indexer, which shared the same physical disk.
Much later we would learn that the problem was in the tags table. In the early days of Pinboard, I had set it up like this:
create table tags tag char(255), bookmark_id int, .... unique index (tag, bookmark_id) charset=utf8
Notice the fixed-length char instead of the saner variable-length varchar. This meant MySQL had to use 765 bytes per tag just for that one field, no matter how short the actual tag was[***]. I'm sure what was going through my head was something like 'fixed-width rows will make it faster to query this table. Now how about another beer!'.
Having made this brilliant design decision, I so thoroughly forgot about it that in later days I was never able to figure out why our tags table took forever to load from backup. The indexes all seemed sane, and yet it took ages to re-generate the table. But of course what had happened was the table had swollen to monstruous size, sprawling over 80 GB of disk space. Adding to this table and updating its bloated index consumed three quarters of the write time for every bookmark.
Had I realized this that fateful afternoon, I might have tried making some more radical changes while my mind was still fresh. But at that moment the full magnitude of what we were dealing with hadn't become clear. We had had big spikes in attention before (thanks @gruber and @leolaporte!), and they usually faded quickly after a couple of hours. So I focused my efforts on answering support requests. Brad DeLong, the great economics blogger, was kind enough to collect and publish our tweet stream from that day for posterity.
We had always prided ourself on being a minimalist website. But the experience for new users now verged on Zen-like. After paying the signup fee, a new user would upload her delicious bookmarks, see a message that the upload was pending, and... that was it. It was possible to add bookmarks by hand, but there was no tag cloud, no tag auto-completion, no suggested tags for URLs, the aggregate bookmark counts on the profile page were all wrong, and there was no way to search bookmarks less than a day old. This was a lot to ask of people who were already skittish about online bookmarking. A lot of my time was spent reassuring new users that their data was safe and that their money was not winging its way to the Cayman Islands.
At seven PM Diane ran out for a bottle of champagne and we gave ourselves ten minutes to celebrate. Here I am watching three hundred new emails arrive in my mailbox.

To add spice to the evening, our outbound mail server had now started to crash. Each crash required opening a support ticket and waiting for someone in the datacenter to reboot the machine. Whenever this happened, activation emails would queue up and new users would be unable to log in until the machine came back online. This diverting task occupied me until midnight, at which point I had been typing nearly nonstop for eleven straight hours and had lost about fifty IQ points. And imports were still taking longer and longer; at this point over six hours.
Pinboard has a three-day trial period, and I was now having nightmare visions of spending the next ten days sitting in front of the abysmally slow PayPal site, clicking the 'refund' button and sniffling into a hankie.
My hope had been that we could start to catch up after California midnight, when web traffic usually dies down to a trickle. But of course now Europe was waking up to the Yahoo news and panicking in turn. There was no real let-up, just the steady drumbeat of new import files. At our worst we fell about ten hours behind with imports, and my wrists burned from typing reassuring emails to nervous new customers explaining that their bookmarks, would, in the fullness of time, actually show up on the big blank spot that was their homepage. We added something like six million bookmarks in the first 24 hours (doubling what we had collected in the first year and a half of running the site), another 2.5 million the following day, and a cumulative ten million new bookmarks in that first week.
This graph shows the average expected time in minutes users had to wait after uploading their stuff:

It wasn't until dawn that the import lag started to decrease. It was now Friday immediately before Christmas week, and I felt if we could steer the site safely into the weekend we would get some breathing room. Saturday night would be the perfect time to run the expensive ALTER TABLE statement that would fix the tags issue. Comforted by this thought I went out for a run (because why not?), and then dived into bed with iron instructions to be awakened ninety minutes later, no matter how much I cried.
Fully refreshed, I could turn my attention to the next pair of crises: tag clouds and archiving.
Tag clouds on Pinboard are a simple UI element that shows the top 200 or so tags you've used on the right side of your home page. Since I had turned off the script that made the clouds, new users were apprehensive that their tags had not imported properly.
Up to this point I had generated tag clouds by running a SQL query that grouped all a user's tags together and stored the counts in a summary table. Anytime a user added or edited a bookmark they got thrown on a queue, and a script lurking in the background regenerated their tag counts from scratch. This query was fairly expensive, but under minimal load it didn't matter.
Of course, we weren't under minimal load anymore. The obvious fix was to calculate the top tags in code and only update the few counts that had changed. But coding this correctly was surprisingly difficult. The experience of programming on so little sleep was like trying to cook a soufflé by dictating instructions over a phone to someone who had never been in a kitchen before. It took several rounds of rewrites to get the simple tag cloud script right, and this made me very skittish about touching any other parts of the code over the next few days, even when the fixes were easy and obvious. The part of my brain that knew what to do no longer seemed to be connected directly to my hands.
The second crisis was more serious. For an an extra fee, Pinboard offers archival accounts, where the site crawls and caches a copy of every bookmark in your account. New users have the option of signing up for archiving from the start, or upgrading to it later. A large number of recent arrivals had chosen the first option, which meant that we had a backlog of about two million bookmarks to crawl and index for full-text search. It also meant we had a significant group of new users who had paid extra for a feature they couldn't evaluate.[****]
Like many other parts of the service, the crawler was set up to run in one process per server. It was imperative to rewrite the crawler script so that multiple instances could run in parallel on each machine, and then set up an EC2 image so that we chew through the backlog even faster. The EC2 bill for December came to over $600, but all the bookmarks were crawled by Tuesday, and my nightmare of endless refund requests didn't materialize.
On Monday our newly provisioned server came on line. Figuring that overkill had served me well so far, this one had 64 GB of memory and acres of disk space. On Tuesday morning I was invited to appear on net@night with Leo Laporte and Amber MacArthur, who were both terrifically encouraging. At this point I could barely remember my own name. And then, mercifully, it was Christmas, and everyone got offline for a while.
In these writeups it's traditional to talk about LESSONS LEARNED, which is something I feel equivocal about. There's a lot I would have done differently knowing what was coming, but the whole thing about unexpected events is that you don't expect them. Most of the decisions that caused me pain (like never taking the time to parallelize background tasks) were sensible trade-offs at the time I made them, since they allowed me to spend time on something else. So here I'll focus on the things that were unequivocally wrong:
Too many tasks required typing into a live database
It is terrifying and you are very tired. At the outset Peter and I had to do live SQL queries to find user accounts, fix names, emails, and logins, and do other housekeeping tasks. I lived in constant fear of forgetting a WHERE clause.
We had no public status page
I could have avoided a very large volume of email correspondence by having a status page to point to that told people what services were running and which were temporarily disabled.
I assumed slaves would be within a few minutes of the master
There were multiple places in my code where I queried a slave and updated the master. This only works if you don't care about being many hours out of date. For example, it would have been fine for the popular page, but was not acceptable for bookmark counts.
There were also some things that went well:
We used dedicated hardware
To quote a famous businessman: "It costs money. It costs money because it saves money".
We charged money for a good or service
I know this one is controversial, but there are enormous benefits and you can immediately reinvest a whole bunch of it in your project *sips daiquiri*. Your customers will appreciate that you have a long-term plan that doesn't involve repackaging them as a product.
If Pinboard were not a paid service, we could not have stayed up on December 16, and I would have been forced to either seek outside funding or close signups. Instead, I was immediately able to hire contractors, add hardware, and put money in the bank against further development.
I don't claim the paid model is right for all projects that want to stay small and independent. But given the terrible track record of free bookmarking sites in particular, the fact that a Pinboard account costs money actually increases its perceived value. People don't want their bookmarks to go away, and they hate switching services. A sustainable, credible business model is a big feature.
So that's the story of our big Yahoo adventure - ten million bookmarks, eleven thousand new users, forty-odd refunds, and about a terabyte of newly-crawled data. To everyone who signed up in the thick of things, thank you for your terrific patience, and for being so understanding as we worked to get the site back on its feet.
And a final, special shout-out goes to my favorite company in the world, Yahoo. I can't wait to see what you guys think of next!
* The list also included the mysteriously indestructible Yahoo Bookmarks, though that didn't seem to affect anyone. How Yahoo Bookmarks has persisted into 2011 remains one of the great unsolved mysteries of computer science.
** I should point out that Yahoo claims Delicious is alive and well, and will bounce back better than ever just as soon as they can find someone — anyone — to please buy it. Since the entire staff has been fired and the project is a ghost ship, I'm going to stick with 'demise'.
*** This is because utf8 strings in MySQL can be up to three bytes per character, and MySQL has to assume the worst in sizing the row.
**** I ended up extending the refund window by seven days and giving everyone a free extra week of archiving.
—maciej on March 08, 2011

A year ago today this site left the comfortable womb of beta testing and started charging for new accounts.
Here are some of our vital signs, one year in:
- 3.5 million bookmarks
- 11.2 million tags
- 2.5 million urls
- 187 GB of archived content
- 99.91% uptime (6 hours offline)
And here are some of the features we've added to the site in our first twelve months:
- bookmark archiving (paid feature)
- API
- view bookmarks filtered by source
- WordPress plugin
- plain-text notes
- auto sync with instapaper, twitter, google reader, read it later, delicious
- twitter archive
- post bookmarks by email
- downloadable bookmarks for offline viewing
- mobile site
- click history page
- bulk editing widget
- tag clouds and widgets
- a quick 'organize' interface for mass tagging
- bookmarks for geographical locations
Over the past year, we've had about six hours of cumulative downtime, when the website was unreachable. Both these episodes were due to hardware failure. This year, we'll work to make the site a little more resilient against hardware trouble.
We also have a long list of bugs to squash and new features to roll out in an effort to make sure Pinboard remains the best value for your bookmarking dollar. I've updated the site roadmap to reflect our development priorities.
If you don't see a feature you want, or if you have specific questions about our plans for the site, please don't hesitate to ask on the Google group.
A site like this is a real pleasure to work on. I would like to offer a slice of virtual birthday cake to all our users, and thank everyone who submitted bugs, gave us feature suggestions, and took a chance on us in our first year. (Please, limit one slice per customer.)
I also owe a big birthday thank you to honorary co-founder Peter, who has helped me keep the site running while keeping a sharp eye out for customer requests. When you want the quality of customer care that only two Eastern European introverts can provide, choose Pinboard.in.
—maciej on July 09, 2010
Auto-import bookmarks from Twitter
You can now turn on a setting that will monitor a Twitter username and automatically add any bookmarks posted to their public stream.
Tweets containing URLs will post as a regular bookmark, with the 'toread' flag set, and the tag 'from:twitter' automatically added. Any #hashtags that appear in the tweet will be converted into a pair of tags - one of them with the prepended hash, and one without (so for a tweet containing '#foo', pinboard will add tags 'foo' and '#foo').
Pinboard will dereference any shortened URLs to their full form before saving the bookmark. It will also try to get the title of the link to use as the bookmark title. In cases where that doesn't work, the title will post as "Untitled (URL)".
Let us know what you think on the Google group!
—maciej on August 14, 2009
I've enabled bookmarking by email for those who want it - see settings and the howto page for details.
—maciej on August 07, 2009
Import should now work with bookmarks in Netscape format—that means you can export your bookmarks from Firefox and Google Bookmarks and upload them on the 'settings' page.
—maciej on August 06, 2009
| « earlier | later » |
Pinboard is a bookmarking site and personal archive with an emphasis on speed over socializing.
This is the Pinboard developer blog, where I announce features and share news.
How To Reach Help
Send bug reports to bugs@pinboard.in
Talk to me on Twitter
Post to the discussion group at pinboard-dev
Or find me on IRC: #pinboard at freenode.net